Exception handling in Java apps for AWS Lambda with retry mechanism
Last week I had a task about injecting a retry mechanism in some apps that were executed as AWS Lambdas. These lambdas are triggered by notification from SQS, so retry mechanism implemented in my company can retry message processing (by changing its visibility), or can also pause, or skip processing.
What inputs for the task I had.
- Our internal SDK for Java apps that are hosted in Lambda and ECS services. The simple schema below describes the SDK’s structure. I’m going to speak about this SDK a lot because it has skeletons for different apps that’s why the entry point for most of lambdas is located here.

- Java-based lambdas (closely connected with SDK)
- Retry mechanism logic from our internal platform (Kotlin oriented).
My first step was verifying the retry mechanism. Now I can say that It’s a file with processSqsMessageWithRetryMechanism suspend method which accepts another suspend method with business logic of message processing. And there is a try{}catch{} block handling three types of exceptions — LambdaRetryableException, MessageSkippedExceptionand Throwable, and then based on these types the execution process is transformed.
So what conclusion to make — I need to put a lambda’s business logic to the method with retry mechanism and throw case-specific exceptions to cause retrying, skipping or pausing. Of course, I also need to add dependencies with the exceptions and the processSqsMessageWithRetryMechanism method, and wrap the core method from a Java-based lambda to Continuation.
As I already said, the entry point for lambdas is implemented in our SDK so I just changed one class in the green rectangle from the first schema.
final var lambdaContinuation = new LambdaContinuation();
...
continuation -> {
objectWithBusinessLogic.acceptWithRetryPolicy(dummyArg);
lambdaContinuation.complete(Unit.INSTANCE);
return "";
}, lambdaContinuation);Where LambdaContinuation is a class extending CompletableFuture and Continuation.
Then I started analyzing pipelines in lambdas to define rules to identify what case is retriable and what — not.
Rules were pretty simple:
- If external API replied with some error (S3 / SQS/ 3rd party) -> retry
- Error about downloading/publishing file from/to S3 via AWS SDK -> retry
- Other internal exceptions (like failed mapping) -> pause
- No cases for skipping messages.
Ok, let’s look at the pipeline of general lambda logic.
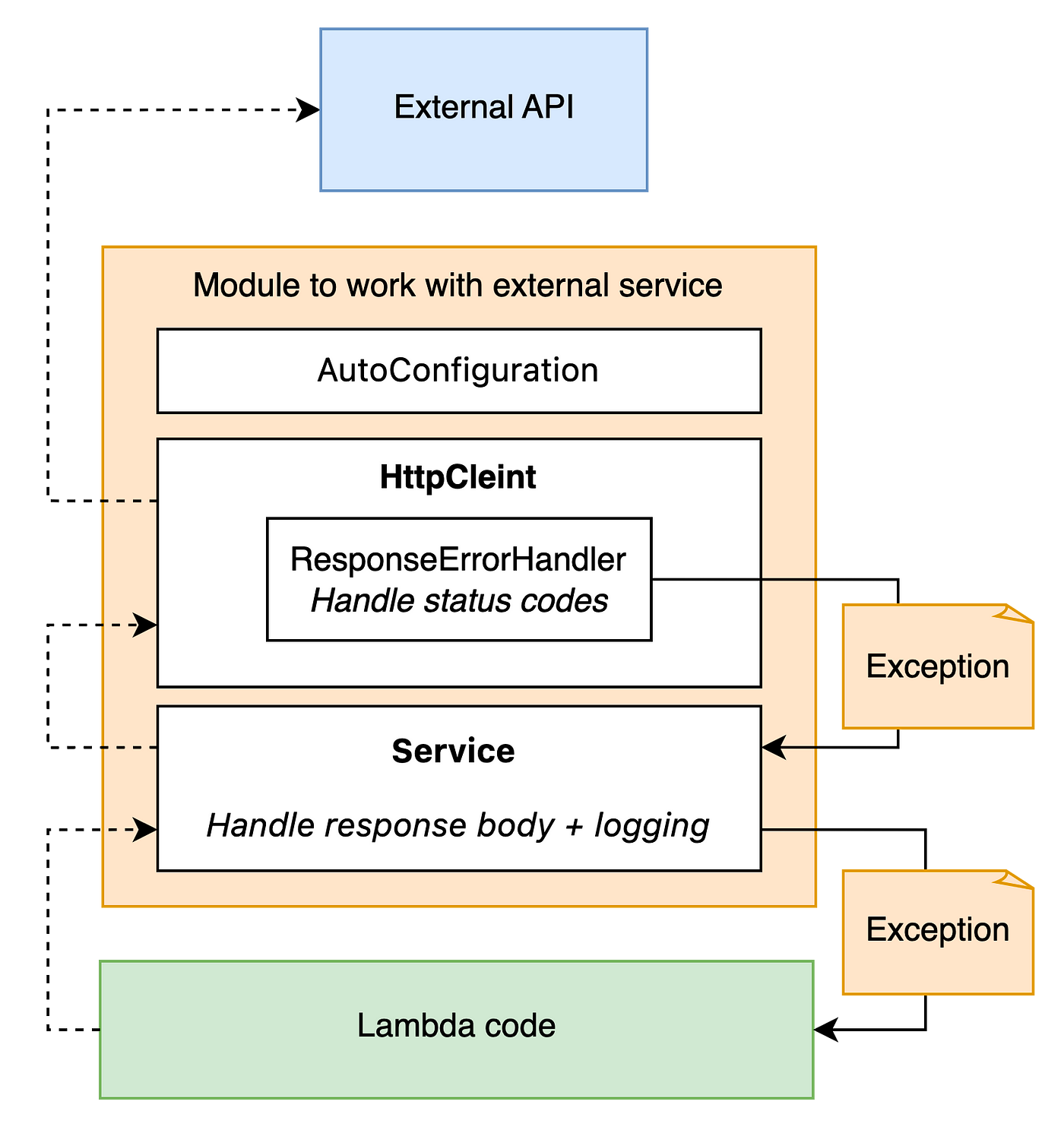
If we revert arrows, a client making a callout is the first entity that can handle a response. But we should remember that the client doesn’t know a lot of business logic, it can operate only with response status code. So the client is the first source of exceptions — of some special exceptions (if we know how to map bad status code to concrete bad cases) and general one — IncorrectResponseException.
Then an exception or normal response processing goes through service. Response can be validated there, and if something is wrong, an exception is thrown. Besides, the exception from the client is also caught and logged, because the service knows more context and can populate it in a log.
Now the exception (or normal response processing) goes to lambda specific code blocks, it means that decision about whether it is retriable or not we make only here. It was the most interesting part of the task because an implemented approach should be clean and scalable for new code blocks.
Back to the first step to remember about how to trigger retrying — need to throw LambdaRetryableException. It means that we just need to catch an exception about retriable case and convert them to ones of LambdaRetryableException type. That’s exactly what I started doing. Buuut when I changed more than 50 classes, I realized how many boilerplates I produced. (Besides, I didn’t understand how to log such cases).
- Back to classes of services (from orange rectangle) and cleaned up all log messages. I’ve already written that a service is the best place to write logs but I had to refactor most of the orange classes to implement this concept (we hadn’t followed some strict rules about it).
- After that I implemented a construction bellow for classes from green rectangle which has an entry point to business logic wrapped by
processSqsMessageWithRetryMechanismmethod.
protected void convertExceptionWithRetryPolicy(Exception e) {
if (e instanceof RetryableException
|| e instanceof IncorrectResponseException) {
throw LambdaExceptionService.createRetryableException(e);
}
}As it stands, an incorrect response is reason to retry (I think it’s clear case). But look at RetryableException. It’s an interface to mark some existing and new exceptions (exceptions from green rectangle). Let’s check a sample to figure out how it works. Now imagine AWS SDK instead of external API.

Yes, I just follow Item 73 from “Effective Java” book
Throw exceptions appropriate to the abstraction .
And I had to make a decision — throw LambdaRetryableException when I catch an exception that should be retryable or throw one that marked by RetryableException… I’ve chosen the second option because
- Exception has normal name describing exceptional case with some details (
FailedObjectPublishingToS3Exception) - It can give some flexibility for future refactoring the whole project if we will change hosting provider, I will be able to use the same exceptions and just remove
RetryableExceptioninterface instead of removing using lambda-specific service from all classes using it.
Finally, I ran existing tests and wrote some new — all were passed. Merged.
